ABSTRACT
This document deals with Image segmentation. The topic is initially dealt with starting from a historical mention of image segmentation techniques before the advent of modern machine learning technology and then being explained generically. Subsequently, an important space is left to deepen the image segmentation techniques based on machine learning and their most common applications (with particular mention to the biomedical field), associated advantages and disadvantages and future innovations in this particular sector.
INTRODUCTION
In research and image processing, people are often interested only in certain parts of the images as they are more significant, these parts are often referred to as targets or foregrounds Image segmentation therefore means the process of dividing the image into characteristic areas, this allows for a more effective subsequent processing by extracting objects of interest from the same specific areas.(1)
Specifically, segmentation is the process by which image pixels that have common characteristics are classified, therefore each pixel in a region is similar to the others in the same region for some property or characteristic (color, intensity or texture). Adjacent regions therefore differ greatly in at least one of these characteristics. The result of a segmented image is a collection of significant segments that collectively cover the entire image.(2)
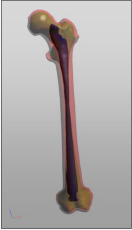
A segmented left human femur model is shown below as an example. The significant regions are the outer surface (red), the surface between the cortical bone and the spongy bone (green) and the surface of the bone marrow (blue).
HISTORY
The development of image segmentation has been a long accumulation of new technologies that have combined with external conditions to meet qualitative changes. Before 2000, for example, we used several methods in digital image processing: threshold segmentation, region segmentation, edge segmentation, texture features, clustering and so on. These methods do not make use of particular and more recent techniques of Machine learning and some of them will be detailed below:(3)
Thresholding, for example, is the simplest way to segment images without resorting to more complex technologies. From a grayscale image, the method can be used to create binary images.
The method consists in cataloging the pixels as “object pixel” or “background pixel” if their value exceeds or not a certain predetermined threshold. Usually the output binary image has a value equal to “1” where the object is present and equal to “0” for the background, thus obtaining a black and white image. The threshold therefore represents a key parameter and gives the name to the method itself, the value can be chosen by hand or automatically. A simple method would be to choose the mean value or the median as the threshold value. This logic can work well in an image without any kind of noise, otherwise you must necessarily use more sophisticated and precise techniques, such as creating a histogram and observing where there is the lowest point in the middle of the histogram; then you choose that value as the threshold.
An example of a segmented image by thresholding (top) compared to the original (bottom) is given below:(4)
 Edge segmentation, instead, is a segmentation method used for the purpose of marking points in a digital image where light intensity changes abruptly. This operation removes a lot of information from the image as the interest is only the information on the different geometric structures recognized by the edges detected in the image.
Edge segmentation, instead, is a segmentation method used for the purpose of marking points in a digital image where light intensity changes abruptly. This operation removes a lot of information from the image as the interest is only the information on the different geometric structures recognized by the edges detected in the image.
The methods for recognizing contours are essentially divided into two main categories:
- Search-based methods → they recognize the edges looking for the maxima and minima of the first order derivative of the image. Examples are the Roberts, Prewitt or Sobel algorithms;
- Zero-crossing methods → they look for the points where the derivative of the second order passes through zero. An example is the Marr-Hildreth algorithm.
Below is an example of input (top) and output obtained (bottom):(5)

Clustering methods, on the other hand, represent a set of multivariate data analysis techniques with the aim of selecting and grouping homogeneous elements in a data set. Clustering techniques are based on measures relating to similarity or, conversely dissimilarity, between elements.
In many approaches this measure is conceived in terms of distance in a multidimensional space. The effectiveness of the analyzes obtained by the clustering algorithms depends very much on the choice of the metric, and therefore on the method chosen for calculating the distance.
An example of an algorithm is QT clustering, invented for gene clustering. In this case the distance between a point and a group of points is calculated using the complete concatenation, ie as the maximum distance from the point of each member of the group.
An alternative method that however makes use of unsupervised machine learning, instead, is K means.(6)
Returning to the history of the evolution of image segmentation, from 2000 to 2010 there were 4 main methods such as graph theory, clustering, classification and combination of clustering and classification.
Finally, since 2010, neural convolution networks (CNN) have established themselves as a tool for image segmentation, they are much more efficient as they are able to learn hierarchical characteristics automatically.(3)
DETAILED EXPLANATION (DESCRIPTION)
Image segmentation is the first step in image analysis and processing, for example for pattern recognition, which directly determines the quality of the final analysis result. It is a process that consists in dividing the images into different and characteristic regions in such a way that the union of the adjacent regions is not homogenous.
A formal definition of image segmentation is showed below: If P() is a homogeneity predicate defined on groups of connected pixels, then segmentation is a partition of the set F into connected subsets or regions (S1; S2; :::; Sn) such that
![]()
The uniformity predicate P(Si) = true for all regions, Si, and P(Si [ Sj) = false, when i =! j and Si and Sj are neighbors.
Image segmentation techniques were initially designed for gray-level monochrome images and then extended to color images by using R, G and B or their transformations (linear / non-linear). The segmentation of color images has attracted more and more attention as color images generally have more information and also thanks to the rapid technological rise of PCs, with the current computing power it is possible to process color images without any kind of problem.
The approach to segmentation of monochrome images consists of detecting discontinuities and / or homogeneities between the gray levels in the image, grouping common pixels into their respective regions and then subdividing (segmenting) the image.
The approaches based on homogeneity include thresholding, clustering, region growing, and region splitting and merging.
As for the color, however, it is perceived by humans as a combination of R (red), G (green) and B (blue) which are also defined as the three primary colors. From the representation R, G, B, we can also derive other types of color spaces using linear or non-linear transformations. Different color spaces, such as RGB, HSI, CIE, L * u * v * are used in the segmentation of color images, but none of them can predominate over the others for all possible types of images.
The components of the RGB space can be represented by the brightness values of the scene obtained through three separate filters (red, green and blue), defining the following equations:
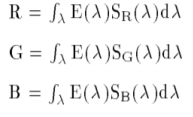
where SR, SG, SB are the color filters on the incoming light or radiance E(λ), and λ is the wavelength. The problem of linear color spaces, however, is the high correlation between the three components in terms of intensity which therefore consists in a close dependence that does not allow to effectively distinguish lights, shadows and shades in color images.
Fortunately, most grayscale image segmentation techniques can be extended to color images such as histogram. thresholding, clustering, region growing, edge detection, fuzzy approaches and neural networks. The segmentation methods can be applied directly to each color component and the results are combined to obtain a segmentation of the overall image.
Segmentation can be also viewed as image classification problem based on color and spatial features. In this case segmentation methods can be categorized as:
- Supervised algorithms → for example Maximum Likelihood, Decision Tree, K Nearest Neighbor, Neural Networks, etc;
- Unsupervised algorithms → for example adaptive thresholding, fuzzy C-means, SCT/center split, PCT)/median cut, split and merge, multiresolution segmentation.
TYPES OF MACHINE LEARNING ALGORITHMS FOR IMAGE SEGMENTATION
As previously introduced, image segmentation can also be seen as a computational process of image classification. In this case, the machine learning technology is exploited, which in recent years has taken over traditional techniques. The classification is then performed based on color and spatial features, to make it possibile the basic architecture in image segmentation consists of an encoder and a decoder:
- ENCODER → extracts features from the image through filters;
- DECODER → generates the final output which is usually a segmentation mask containing the outline of the object.
U-Net, for example, is a convolutional neural network that was initially designed for segmentation of biomedical images. The name derives directly from the organization of its architecture which when displayed resembles the letter U, hence the name U-Net. In terms of organizations, it consists of two parts: a left part (the contracting path) which takes care of capturing the context, and a right part (the expansive path) that is to aid in precise localization. The contracting path is made up of two three-by-three convolutions. The convolutions are followed by a rectified linear unit and a two-by-two max-pooling computation for downsampling.
FastFCN (Fast Fully-connected network), instead, uses a Joint Pyramid Upsampling(JPU) module to replace dilated convolutions to save a lot of memory and time. Basically it consists of a fully connected network (core) and the JPU module for upsampling. JPU upsamples the low-resolution feature maps to high-resolution feature maps.
Another is Gated-SCNN that differs from the previous ones for a particular CNN architecture organized in two-stream. In this model, a separate branch is used to process image shape information. The shape stream is used to process boundary information.
DeepLab, instead, features an architecture where convolutions with upsampled filters are used for tasks that involve dense prediction. Segmentation of objects at multiple scales is garanteed via atrous spatial pyramid pooling. DCNNs are usually used to improve the localization of object boundaries. Atrous convolution is achieved by upsampling the filters through the insertion of zeros or sparse sampling of input feature maps.
Finally, we present Mask R-CNN where objects are classified and localized using a bounding box and semantic segmentation that permit the classification of each pixel into a set of different categories. In Mask R-CNN each region of interest is associated with a segmentation mask, the output returned consists in a class label and a bounding box. The basic architecture was designed and conceived as an extension of Faster R-CNN, the latter is made up of a deep convolutional network that proposes the regions and a detector that utilizes the regions.(8)
APPLICATIONS
Image segmentation can be applied to different fields such as e.g. pattern recognition, image compression, and image retrieval, these tasks are required in countless sectors, especially the biomedical. In fact, up to now, lots of image segmentation algorithms exist and be extensively applied in science and daily life.(9)
Diagnostic imaging, for example, is a fundamental tool in the biomedical sector. Established applications such as magnetic resonance imaging (MRI), computed tomogrophy (CT), x-ray radiography (RX) and other imaging modalities allow non
invasive mapping of a subject’s anatomy and are a key component in diagnosis and in treatment planning. The segmentation algorithms, in the computational processing of such biomedical images, provide an important support in the quantification of tissue volumes, diagnosis and localization of the pathology, study of the anatomical structure, treatment planning, correction of the partial volume of functional imaging data and integrated computer surgery. Methods for performing segmentations vary widely depending on the specific application, imaging modality, and other factors. For example, the segmentation of brain tissue has different requirements from the segmentation of the liver, so there is currently no single segmentation method that yields acceptable results for every medical image.. General imaging artifacts such as noise, partial volume effects, and motion can also have significant consequences on the performance of segmentation algorithms.
There are also more general methods that can be applied to a wider variety of data, however the methods that they specialize for particular applications can often get better performance by taking taking into account previous knowledge. An example of different output on the same object obtained through the application of different methods is shown below.
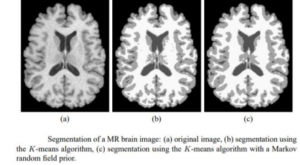
The selection of the approach and method to be used therefore represents the greatest challenge and requires an important previous knowledge both in terms of image segmentation and application experience of the segmentation algorithms.(10)
ADVANTAGES/DISADVANTAGES
The advantages and disadvantages related to the use of image segmentation are both specific to the individual segmentation techniques, and generic and related to the use of machine learning. The recognition of the strengths and weaknesses of the different segmentation techniques is therefore fundamental for the choice of the approach in the various specific applications.
One of the most commonly used methods (also described above) is the threshold method. In this method, the image pixels are divided with the help of intensity level of an image. This method is mainly used to distinguish objects in the foreground from the background images. Among the main advantages there are certainly the simplicity of implementation and the speed of response, as well as the good effectiveness on some particular types of images (e.g. documents, controlled lighting). However, the algorithm is not flawless, there is no guarantees of object coherency — may have holes, extraneous pixels, etc.
Another widely used method is the Region Based Segmentation Method, based on segmented an image on the basis of similar characteristics of the pixels. Unlike the previous method connected regions are guaranteed and IQM reduces length neighbor problems during merging (main advantage). The main drawback, on the other hand, is that the position and orientation of the image lead to blocky final segmentation and regular division leads to over segmentation (more regions) by splitting.(11)
The advantages and disadvantages of segmentation techniques, finally, are then combined with those of machine learning
including the reduction of human error (which is the main advantage), but also the time required for the acquisition of data for the training process that it is often laborious and rapresents the main drawback from machine learning tecnhology.
FUTURE INNOVATIONS
The future of image segmentation techniques is closely linked to the continuing evolution of machine learning. The crucial points that could mark the near future are the evolution of improved unsupervised algorithms and the increasingly marked introduction of robots based on artificial intelligence. Unsupervised algorithms, in fact, are left to work on their own, they discover and identify hidden patterns or groupings within a data set that would not have been identified using supervised algorithms. Their further development would give an important impetus to the implementation of artificial intelligence systems that will undoubtedly improve machine learning-based image segmentation techniques and their applications (especially in assisted surgery).
CONLCUSION
This paper has dealt with the problem of image segmentation starting from a generic introduction and deepening their techniques based on machine learning. It is evident that these techniques are now established and used in many sectors, especially the biomedical one in which they are the basis of the most common diagnostic techniques, but it is reasonable to expect that the evolution of machine learning will accompany their important boost in the coming years. This will certainly increase their usefulness even in the most everyday applications, thus overcoming the current application limits.
LIST OF REFERENCE
- Nabil MADALI (2020) ‘Introduction To Image Segmentation’ [Online], available at:
https://towardsdatascience.com/introduction-to-image-segmentation-9636fa95922
- WIKIPEDIA ‘Image segmentation’ [Online], available at:
https://en.wikipedia.org/wiki/Image_segmentation - Eai Fund Offical (2018) ‘History of image segmentation’ [Online], available at:
https://medium.com/@eaifundoffical/history-of-image-segmentation-655eb793559a - WIKIPEDIA ‘Thresholding (image processing)’ [Online], available at:
https://en.wikipedia.org/wiki/Thresholding_(image_proc essing) - WIKIPEDIA ‘Edge detection’ [Online], available at:
https://en.wikipedia.org/wiki/Edge_detection - WIKIPEDIA ‘Cluster Analysis’ [Online], available at:
https://en.wikipedia.org/wiki/Cluster_analysis 7. H. D. Cheng, X. H. Jiang, Y. - Sun and Jing Li Wang ‘Color Image Segmentation: Advances & Prospects’ [Online], available at:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.119.2886&rep=rep1&type=pdf - Derrick Mwiti (2020) ‘Image Segmentation in 2021: Architectures, Losses, Datasets, and Frameworks’ [Online], available at:
https://neptune.ai/blog/image-segmentation-in-2020 - ‘Segmentation turial’ [Online], available at:
https://d1wqtxts1xzle7.cloudfront.net/47879147/Segmentation_tutorial.pdf?1470644346=&response-content-disposition=inline%3B+filename%3DTutorial_Image_Segmentation.pdf&Expires=1619004239&Signature=dl1GRiS1Uvt-2PkJl5Nw0tu0ow6ehg-smzqftOo22e2T4v-Dyp3rRHfT0YI9RxjaGsx60aRQORCcwKTyW6kfY0L5CcuFswDgW9K79Sqk2TGoWpkX8QZfzhZfolT0w9m-fZYqCv6TBSxRKvzwK3oH9xZOelVTzrgXt1lRdY-JFUAbdsofV1A5O2-LrNnAX-sAcwXoBO010Qu7~JQrvjCdSBtijcV2V1~74YuPWE4faCslUhAmABbtQycbzvqxuEtWtcJXPAd9aa88QOco9am~TbtK3IdVFmOZ2INA2T~vhHDT9mAYIt4~bwt6FPdYAGH1fHVf8TqbLBvaiizXxyczLQ__&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA
- Dzung L. Phamy, Chenyang Xu, Jerry L. Prince (1998) ‘A SURVEY OF CURRENT METHODS IN MEDICAL IMAGE SEGMENTATION’ [Online], available at:
https://www.ece.lsu.edu/gunturk/Topics/Segmentation 1.pdf - Anjna, Rajandeep Kaur (2017) ‘Review of Image Segmentation Technique’ [Online], available at:
http://ijarcs.info/index.php/Ijarcs/article/download/3691/3183